
The birth of Albumentations
I would like to talk about Albumentations, an open-source library for image Augmentations. An explanation of how it was born and evolved over time. The text’s primary purpose is to depict its creation, as I would like to have a story to enjoy in 20 years.
I will mainly talk about the library’s origins and cover the process of iterative improvements in fewer details. The text could be more concise, but I prefer to keep unnecessary information for historical purposes.
Albumentations is another python library for image augmentations. It is widely used in Deep Learning tasks, especially with PyTorch.
- Q: What are image augmentations?
- A: Image augmentation is a way to generate a new image from the one you already have. Typically, it is something simple as rotations or reflections but could be more involved, like adding rain or applying style transfer.

- Q: Why do we need this?
- A: Neural networks trained on larger datasets generalize better.
One way to increase the size of the dataset is to collect and label more relevant data. It works well but is expensive and could take some time.
Another way is to apply augmentations. They are not as valuable as adding new data, but you get them for free.
Two methods are not mutually exclusive, and in practice, you combine them.
With augmentations, you extend the pipeline of:
Read image from the disk => feed to the neural network.
with an extra step:
read image from disk => randomly augment it => feed to the neural network
In most computer vision pipelines, the first two steps happen on CPU and the last on GPU.
June 2017 Kaggle organized the machine learning competition Planet: Understanding The Amazon from Space. Participants needed to create a model that assigns tags to images: forest, river, road, etc.
The task was rather dull, very similar to the MNIST classification. Discussing it at ODS.AI, a few experienced Kaggle competitors and I decided to join the challenge.
The problem was not exciting but did not require much work. End2end pipeline could be implemented in one evening. After that, you needed to experiment with hyperparameters and augmentations, which could be done passively.
Augmentation is an excellent regularization. The more augmentations I added - the better my networks behave.
We finished 7th out of 936 teams. We did not get any money, but titles of Kaggle Grandmasters became closer :)
Regarding image augmentations, three things were important:
- The mainstream opinion was that the bottleneck in training was GPU. The more powerful GPUs you have - the faster is network training.
- In the DSTL Satellite Imagery Feature Detection challenge at Kaggle, my team finished 2nd, and I bought a home computer with four powerful GPUs (for 2017).
- For augmentations, we used the open-source library ImgAug. It has a lot of powerful transforms, but it is not optimized for fast execution.

The bottleneck in the Amazon Challenge was the CPU, while GPU utilization was far from 100%.
All team members, including Alexander Buslaev, started building custom augmentation pipelines, trying to make them flexible but fast.
Four months later, in fall 2017, I left a job at TrueAccord, accepted an offer from Lyft (blog post on how I was searching for the job), and took a break.
At the same time, Kaggle hosted Carvana Image Masking Challenge. The task was binary segmentation. I used the pipeline from a previous competition and got to the top 10 on the public leaderboard. Another team from the top 10: Alexander Buslaev and Artem Sanakoyeu, proposed to join the efforts. We merged and finished first, by luck beating the legendary anonymous Bestfitting by 0.000001. (blog post with the solution).
During the challenge, we shared code. I checked out Alexander’s augmentation pipeline. It was elegant and fast, and I liked it.
I had my own and used it to win a few ML challenges, but I was tired of extending and debugging it.
I copy-pasted his augmentations, and for the next six months, we improved them independently. In winter 2018, I won another challenge and achieved the title of Kaggle Grandmaster, while Alexander won SpaceNet and Urban 3d at Topcoder. He used the prize money to buy an apartment :)
April 2018 The team ods.ai: Alexander Buslaev, Selim Sefebekov, and Victor Durnov won Data Science Bowl 2018, finishing 1 out of 3634 teams and were relaxing after this exhausting marathon.
After getting the Kaggle Grandmaster title, I stopped caring about machine learning competitions.
But there was an issue that I wanted to address. I did not have papers about Deep Learning during the job search, which made my life harder.
I wanted to fill my Google Scholar with many deep learning publications and no longer worry about that issue.
I found that CVPR 2018 had a Deepglobe workshop, which had a competition track with three challenges. For every challenge, participants needed to submit a prediction on the test set and a short paper describing the solution for every challenge for all three.
And I found it ten days before the deadline. Ten days for ML competition is too few, and we had not one but three. It did not scare us. Academic ML competitions rarely attract strong competitors, as academia focuses on novelty, not accuracy. Nearly every winning solution in ML competitions is a combination of good existing ideas. Publishing papers and winning competitions are two different sports.
I convinced Alexander Buslaev, Selim Sefebekov and Alexey Shvets to give it a try. In ten days, we trained three models, prepared three submissions, and wrote three papers. Our standing: (2nd, 2nd, 3rd (Paper 1, paper 2, paper 3)
In graduate school, I was frustrated that the Quantum Monte Carlo code that our and other research groups used was floating between scientists in tarballs via emails. Every scientist independently made improvements and fixed bugs, and all 100500 versions lived their own life.
The situation with augmentations started to look similar. I asked Alexander to publish his pipeline publicly to GitHub to avoid it. Even more - I wanted to release the code before the CVPR. I hypothesized that it could attract more people to look at the code, not just people - experts in computer Vision, as CVPR is the top world conference in this field. I proposed to add a link to the GitHub to all three posters that we needed to present.
I wanted to publish the code and make improvements later, and Alexander wanted first to rewrite the code and make it production quality before the publication. It looked like it would take us another couple of years.
At that moment, Alex Parinov joined the initiative. He understood the importance of the infrastructure for efficient problem-solving in ML. He actively participated in Kaggle competitions and contributed to open source. He said that he would help improve the code quality. And this was the last thing we needed to make the code public.
The name for the library was chosen this way: Alexander mentioned the library at work, and his colleague proposed the name Albumentaitons, which is the mix of Albu, the nickname of ALexander BUslaev, and the word “augmentations.” I do not remember the exact details, but it could happen that we picked this name as a temporary, but there is nothing more permanent than temporary, and we never even considered changing it.
June 2018, a few days before CVPR 2018, Alexander published the first commit.
At CVPR 2018, we picked the best sport for posters - near free coffee, but it did not help much. Not that many people paid attention to our posters or our library. But at least we tried :)
June 17, 2018, Alex added tests.
June 21, 2018, Alex added automatically generated documentation with Sphinx.
July 1, 2018, Alex added a benchmark that compared Albumentations to similar libraries. It allowed us to be sure that we were faster, and from that moment, if we had seen that other library made a faster transform, we looked in their code, learned their tricks, and absorbed them into our code.
In that phase, we added all augmentations that we could find. We did it because we could and because it was fun—no meetings, plannings, or writing tech specks. We moved fast, and it gave us drive. It felt good to see the progress. On the other hand, some decisions that we made, for example, names of the transforms or their default parameters, are far from optimal, but when we realized this, it was too late to change.
July 1, 2018. The first pull request from a person who was not on the core team
August 2018: Eugene Khvedchenia joined the team. By that time, he was actively participating in Kaggle competitions, and it was evident that you need to have good augmentations to get to the top. During the Data Science bowl 2018, he moved from Keras to Pytorch and developed his augmentation pipelines.
He moved to Albumentations after the first release. The library looked very similar to the code in the winning solution of the Data Science Bowl 2018, and he liked it. By August, he decided to add the support of bounding boxes to the library, which was valuable. We had images and segmentation masks at the time. His deep understanding of the code and high-quality pull requests were impressive, and thus he became a member of the core team.
During the summer of 2018 we:
- Refactored the code
- Improved test coverage
- Added linters, formatters, improved Docstrings and Readme
We added several Jupyter notebooks with examples on how to use the library. We also added an example of how to move from Torchvision to Albumentations in a few lines of code.
November 28, 2018, Alexander added “multi-target” functionality. It allowed applying the same transform to a set of images, masks, and bounding boxes. We added a jupyter notebook, and later, in 2020, I wrote a separate blog post on the topic.
January 3, 2019, Eugene added keypoints. None of us needed them, but there was a request from users, and Eugene addressed it.
April 7, 2019, Eugene Added Lambda Transform. It allowed adding custom transforms without pain.
May 18, 2019, Alex added serialization. The choice of augmentations is a hyperparameter and should be defined in the config files. Serialization allowed to save/load to/from YAML, JSON, and python dictionaries.
In August 2019, Mikhail Druzhinin started contributing to Albumentations.
He wanted to join the Open Source project, but all projects he was interested in were too complex, or he could not figure out how to have an impactful contribution.
For one of his projects, he needed complex image augmentations. He found ImgAug, stumbled on problems, and created a pull request. He said that it was pretty painful. After this, he wanted to create custom transforms, but the limitations of the architecture of ImgAug made it hard to add. Hence he wrote his augmentation pipeline.
At the end of July 2019, he joined Severstal: Steel Defect Detection at Kaggle and realized that many people in Kernels use Albumentations. He looked at the library’s code and liked the elegance and the simplicity of the interface. Roughly at the same time, I tried to engage people from the ODS.AI community to contribute to the library. I promised we welcome everyone and no need to be shy.
Mikhail had experience optimizing code for weak hardware and instantly found a few places where Albumentations could be made faster. He made a set of high-quality pull requests with new transforms, bug fixes, and enhancements.
September 12, 2019, Mikhail joined the core team.
September 27, 2019, Alexander added Replay mode. Augmentation pipeline is composed of a set of transforms with different probabilities. Applying it twice to the same image will get different results, making debugging ultra hard. Replay/Compose allows full reproducibility when needed.
February 2020 Alex updated documentation and created a website for the project - albumentations.ai. The website looked so good that the author of the Insightface adapted the template for his website insightface.ai :)
July 2020, Mikhail, with the help of Alex, created Albumetations-experimental where experimental transforms are added.
September 2020 Alex created AutoAlbument - a tool that allows an automatic choice of augmentations for the task. By that time, I was not involved in ML projects and sadly did not have a chance to use it.
After that, we did not do anything fundamental.
For the most part:
- Improved the documentation
- Added new, often exotic transforms
- Improved the code quality
April 2021, I met Alex and Mikhail in person. To my surprise, shy Mikhail is huge, a two-meter man, way taller than me :)
How to get the motivation to spend free time on the open-source?
In the beginning, it was just fun. You see how your project evolves and make the changes you want.
After that, we got dopamine boosts when we saw how the adoption grew. Some people even thanked us. Doing good things feels good, and it was a great motivation.
When the library became even more popular, everything changed. On the one hand, we implemented nearly everything we needed ourselves. On the other hand, we started getting bug reports, not about bugs but because users did not understand the documentation or read it.
Free spirit development started to resemble corporate support. We got to this state by spring 2020 and decided to relax and work on the library only when it is fun.
This approach has limitations. We look at pull requests not as often as we could, and bug reports could stay open for weeks. That is life. If you want the process to move faster - feel free to fork the code. The license permits it.
How did we promote the library?
There are many image augmentation libraries (blog post with an overview. We created another one. How to make it popular?
We wanted:
- The library should be fast. At least as fast as competitors.
- The core team should find it easy to use and extend.
- Others should find it easy to use and extend.
- People who are not the core team should know that the library exists.
- Users should recommend the library to each other without us asking for it.
We were addressing the first three points. But what with the last two?
We did not know and just experimented.
Academia
In August 2018, two months after the first release, I asked Alexander Kalinin to write a pre-print for arXiv about the library. The primary purpose was to make it easy for people in academia to cite us. For sure, we could add BibTex to the Readme, but citing GitHub repositories is not widely accepted yet, and many people refuse to do this.
In the beginning, it was self-citations. In 2018-2020 I actively published papers and always cited out pre-print. In the beginning, it was self-citations. In 2018-2020 I actively published papers and always cited out pre-print. But pretty quickly, unknown to us, researchers started to mention our pre-print.
In the summer of 2019, Alexander Kalinin lectured in summer school in Poland. Another lecturer there was Sebastian Raschka. Sebastian mentioned that he is an editor for a special issue to the MDPI and asked if we have anything relevant. Alexander showed the pr-print, Sebastian liked it, and invited him to write a full-scale publication.
We (mainly Alexander Kalinin), wrote the paper, and now it is the most cited paper of that special edition.
What else can we do here? People in academia introduce novel augmentation, and often someone adds them to the Albumentations.
We should write authors, thank them for their work, and mention that their transform is a part of the library.
Machine learning competitions
We worked on the library, competing in various challenges at Kaggle and other platforms. When we finished at the top and published solutions, we mentioned the library and how we used it.
Basically, as in other industries, recommendations of the influencers helped with the promotion, but in our case, we were these influencers.
We needed to decrease the pain of using Albumentations in Kaggle Kernels, and in April of 2019, the library was added to the Kaggle Docker.
If other winners used Albumentations in the solution but did not mention it, I pinged them and asked them to add it to the description of the solution.
But, being honest, I did not need to do it that often. People knew that we work on the library, they understood that when they mention it - it is the way to say: “Thank you for your work,” and they did it.
We created a page in the documentation with the list of competitions where winning teams used Albumentations + the description of the winning solution. Sadly, the page is outdated. I strongly feel that Albumentations is used in almost all winning solutions in Computer Vision challenges, but we do not want to parse competition websites manually.
I like this story. In fall 2019, I helped organize Lyft: 3D Object Detection for Autonomous vehicles challenge organized in conjunction with NeurIPS 2019. At the end of the conference, there was a dinner for all competition organizers.
A man was sitting next to me. I wanted to show off and mention that I am a Kaggle Grandmaster. He did not even understand that I was showing off. Typically only people from the Kaggle community see value in this title. Later in the conversation, he mentioned that the most profound insight from the challenge was that all top teams used Albumentations. His company did not wait till the end, retrained in-house models, and got a considerable improvement. When he learned that I am from the core team of Albumentations, he got excited and proposed to take a photo with me :)
Industry
Taking to computer vision people from various companies, I got an impression that Albumentations is used all over the place, including all FAANG.
But it is unclear how to make this information publicly available on the website.
When I worked at Lyft, I used Albumentations in several training pipelines. I asked the manager if I could add Lyft’s logo to the Readme and got a positive answer. I asked people from other companies, and more logos were added.
In general, the question is open. I do not know how to scale this up.
Open source
I can see 5700 repositories and 144 packets with Albumentations as a dependency.
In this case, it was clear what to do. I needed to take a popular repository with a computer vision training pipeline and rewrite the augmentation part with Albumentations. Repeat many times.
I was ready to do this, but refactoring someone else’s code did not thrill me. Luckily after the library became better known, popular repositories started adopting it.
These are top ten repositories, which have Albumentations as a dependency.
What can we do better?
- We can look for questions at Stack Overflow about image augmentations and answer them with code using Albumentations.
Other experiments
Albumentations were not the only activity where I tried to learn how to do marketing. In 2017-2019 I gave talks in podcasts, conferences, meetups, and I was not allowed to talk about my projects at Lyft. Hence I spoke about Albumentations.
I live in the US and was promoting the library in English.
The rest of the team lives in Eastern Europe and promoted the library in Russian.
October 2019, the library became a part of the PyTorch Ecosystem. It was not hard to get there, but we thought it was very cool. There is even a conference about PyTorch Ecosystem. We could participate and promote the library there, but we were always busy, and it did not happen.
February 2020, we got into the Nvidia Inception Program. We did not plan to get there. Someone told us about this option, we applied and got approved. We got $100k AWS credits for a year and proudly added “Member of the Nvidia Inception Program” to the website. :)
Another small detail. If you look where people come to the repository, you will see link.zhihu.com and link.csdn.net in the top 10 resources for tech people in China.
I asked a student who speaks Chinese to translate my blog post about multi-target and post on the relevant platforms in China. I paid $50 for the work. The idea was - I already wrote the text, prepared pictures. China is huge. Let’s see how it will turn out.
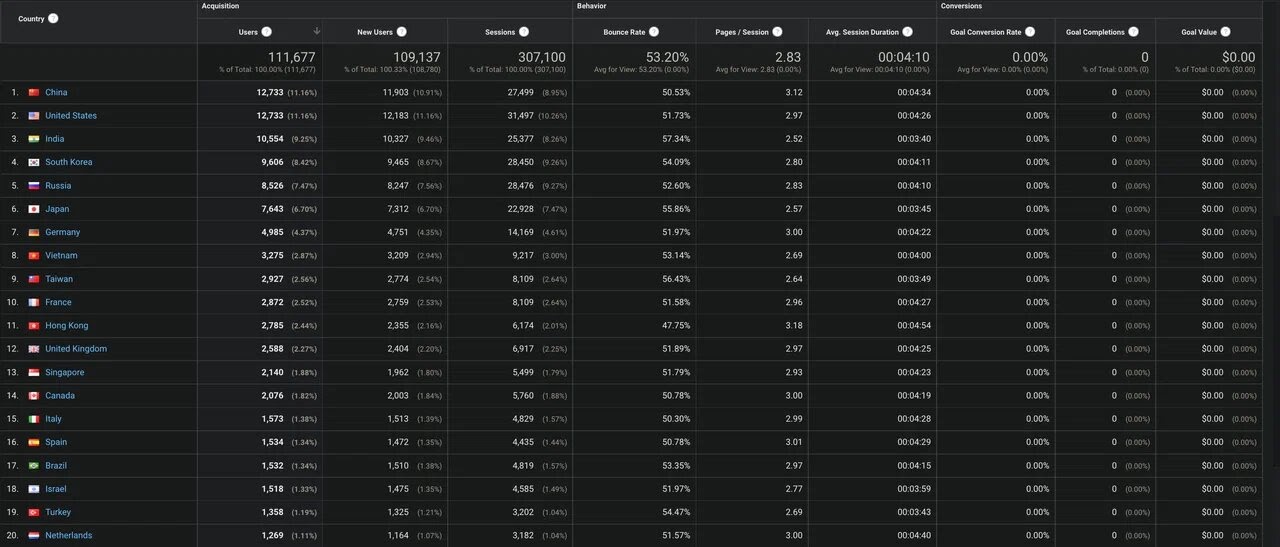
Here is the source of countries who have come to the website for the past year. China is in the first place. There may be a relation between the translation and these statistics, but, most likely, without it, the statistics would be the same. Machine Learning is growing rapidly in China.
Every release of the Library, we did posts to:
Not all, but most of the announcements spread well. I have 6k followers on Twitter; Alexander Kalinin has 4k. It helped.
The product is successful when people who are not affiliated with it write blog posts about it. If we use this metric, Albumentations is a success as people regularly create blog posts mentioning Albumentations.
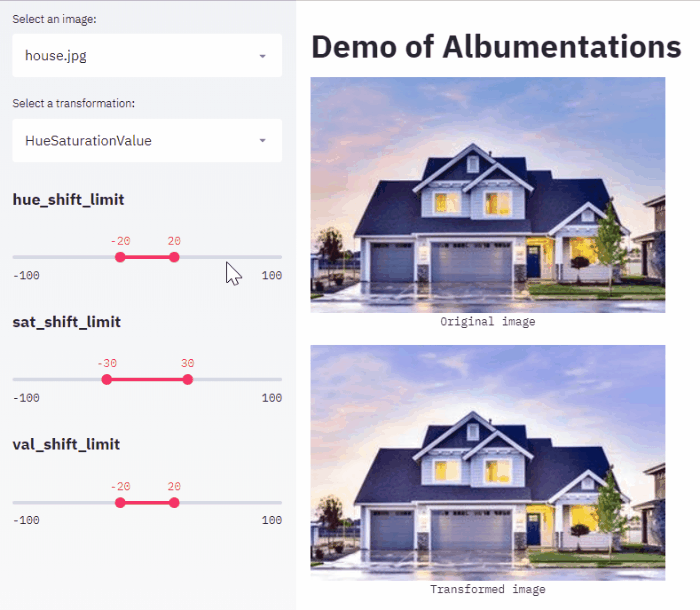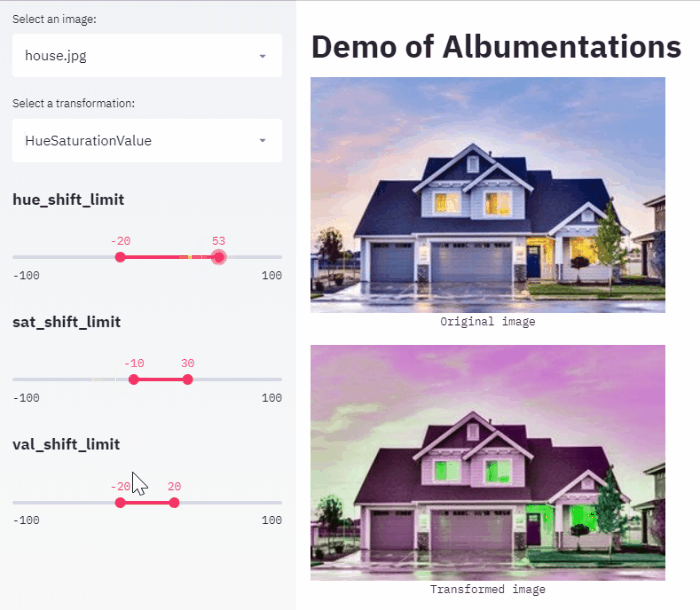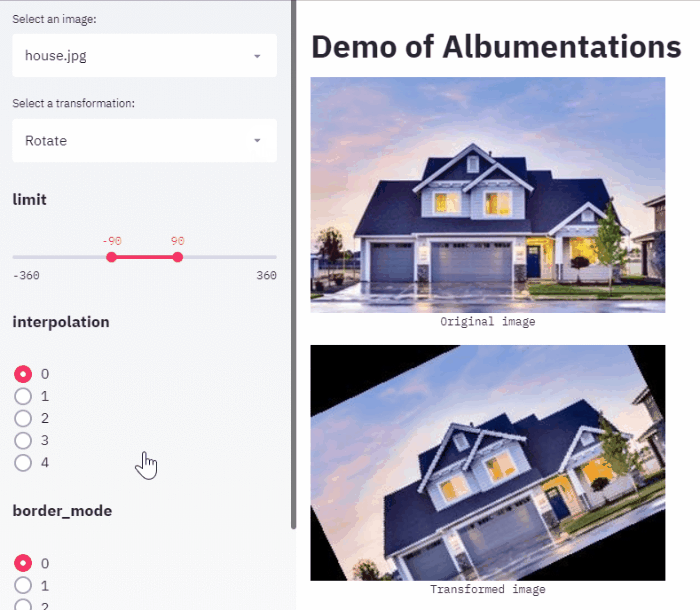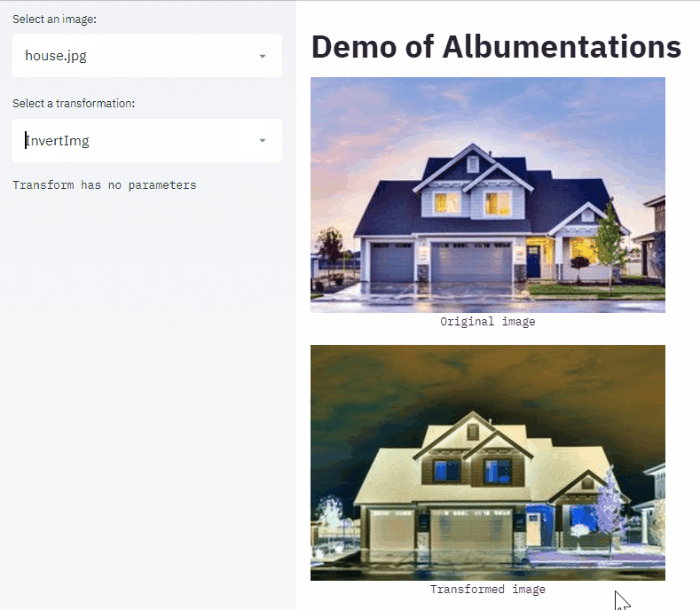
My favorite is one by Ilia Larchenko. He used streamlit to create a web app that allows choosing augmentations and their parameters for a task at hand.
What will I do differently if I will do it again?
It is hard to tell. Right now, I am trying to learn to build a startup. Hence, if I work on open-source, it should have a way to monetize—something like an open-core model, where you have free features for developers and non-free features for the enterprise.
Can I convert Albumentations to Open-core? Most likely, but I cannot figure out how exactly. Maybe someone who reads this post can message me and give a hint?
It is hard to tell, but I would say - most likely. It was a lot of fun. Every time someone said: “Thanks” to us or just mentioned the library, we got dopamine boosts.
As a bonus, I improved my programming skill, and, line: “Co-creator of Albumentations” may have some value.
I use a lot of open-source projects, but I do not know the names of the people who develop and maintain them. Same here. Most people who use Albumentations do not know who the core team is.
But there was an exception :)
This summer, I visited Kyiv. One night one female Data Scientist and I went out and walked in the night city. She used Albumentations at work and knew that I was one of the core developers. It may happen that she would not go out with me if not the library :)
What about metrics?
- More than 2.6 million downloads from PyPI
- 9300+ stars at GitHub
- 450+ citations in scientific papers
- The library was mentioned in 6 books
- The library is used in a few large projects:
- In 2021:
- 110k people visited albumentations.ai
- They had 870k page views
- November 2021:
- 17k visitors
- 100k page views
- People add Albumentations to LinkedIn to the list of skills :)
Conclusion
In the end, I would like to thank the core team and all the contributors. Open source is a bizarre beast. It takes a lot of time to befriend it :)
If you get to this part, I would like to ask for a favor:
- If you use the library at work, could you please ask your manager to add the company’s logo to our website? If yes - you just need to follow this link and fill the form.
- If you use Albumentations in your scientific projects, it would be great to cite our paper.
- Pull requests are greatly appreciated if you found a bug or have ideas on improving the library.
- And of course - if you did not give a star to the repository, it is time to do this :)


{kind=link}
{kind=link}
{kind=link}
Comments