
From Albumentations to Image Search
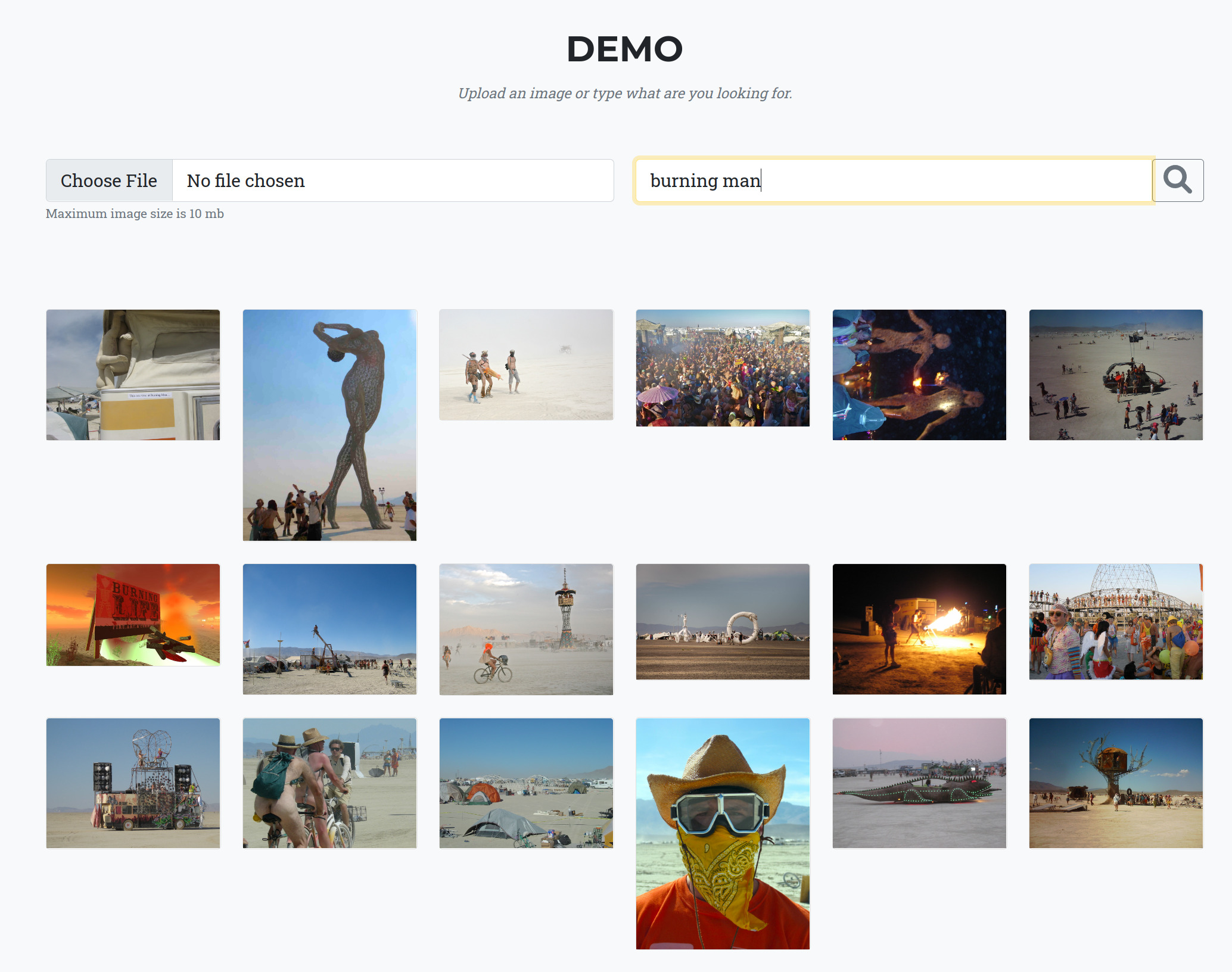
I wrote a Web App that performs Image search on the Open Images dataset (1.7M images).
Here is the link.
You upload an image or perform a text query, and it returns 18 similar ones.
Questions:
- I want to use the service as a part of the pipeline. Can I get access with an API and not a web app?
- 18 is good for a demo but not enough to enrich my training set. Can I get 1000 similar images per call?
- We care about the privacy of the data. Can we have an image search on our data and hardware?
- Can we get an image search on some other dataset? COCO, ImageNet, something medical?
- We want to use the data to train models. Can the service return segmentation masks, bounding boxes, and class labels in addition to the images?
- It works fast on 1 million images. Will it be fast on 1,000,000,000 images?
-
Right now, we perform a search using a sample image. Can we use text to describe what we want?
- The answer to all these questions is a solid yes.
I need to admit that it is unclear how image search will work with other domains. At the moment, everything is designed to work on natural images.
To be applied to medical or satellite, I will need new models, and I do not have them in front of me. If there is interest, we can explore this option.
I have a request — if you have an idea how your product may benefit from an image search, do me a favor, and write in the comments or message on LinkedIn.
All ideas, including wild ones, are welcome.
Right now, I have in mind:
- On public data: Company has a limited amount of data. The model is not performing well on a set of images in the test set. The company uses API to get 100 similar images for every “hard” sample, label them, and add them to the train set.
- On your data: The same as above, but on the company’s private data.
- On your data: Faster data labeling. For every image, you find a set of similar images. If all belong to the same class, you add a label to all 20 images in the cluster. => 20x to the data labeling performance.
- On your data: QA for data labeling. When I checked data labeling quality at segmentation masks or bounding boxes on the image, I was unsure if it was perfect or just good. But looking at the cluster of similar labeled images made the limitations of the labels evident.
An important part is over. The rest is just for the logging.
Q: How did I get the idea to implement a service for image search?
In my free time, I participate in developing the Albumentations.AI.
Albumentations is an open-source library for image augmentations.
For more details on how the library was born and evolved, feel free to check — The Birth Of Albumentations.
At some point, we had five members in the Core Team.
A couple of years ago, the library became mature, and how we work on it changed.
Originally it was a fun project we did for ourselves, but after it became popular, it started resembling maintenance and support.
At this point, Alexander Buslaev (the library was named after him ) left the project. I started to invest much less time as well.
And then there were four of us.
In February, Russia invaded Ukraine, and Eugene Khvedchenya, who lives in Odesa, Ukraine, left the project. When Russian rockets hit buildings around him, he shifted his focus from the library to things that are more important in life.
And then there were three of us.
The shock of the war hit as hard as well. We did not look at the library for months.
Even more, we started the library because we needed it to train ML models, but in the past years, we moved to other activities.
By May of 2022, we had at GitHub:
On the one hand, the project was quite popular; on the other — it had all chances to die.
We needed someone to pick the work up.
First idea: we were thinking of finding a motivated ML Engineer who will work on the project as we did at the beginning. The problem is that motivation comes and goes, and we would need someone new at some point.
Second idea: Add a new person to the Core Team. As I wrote in The Birth Of Albumentations, we invited to the Core Team people who actively contributed to the project with high-quality Pull Requests. We contacted one such person, but he was busy working on his Open Source project.
Third idea: Find $5000 per month, and hire a person to work on a project full time.
I asked around about how to find money in such a situation.
There are two ways:
- Donations.
- Build a company on top of the Albumentations in an Open Core way. I.e., the library is free as it is now, but there are paid features like privacy or security that are needed in the enterprise. Another new thing was that I and startup founders think about the value of the library differently:
I:
- Blazingly fast.
- Great functionality.
- Wide range of transforms for different domains.
- Easy to extend.
Startup founders:
- Brand
- Community
- The fact that the library is already integrated into thousands of companies.
For a few weeks, I interviewed people who use the library in production.
I collected the feedback (blog post with the summary — Albumentations: Feedback) and looked for pain points that could be addressed with a product.
No luck. I could not find an idea on how to use augmentations to solve significant pain.
I think the main reason is that building tooling for developers is a horrible business idea.
A better one would be to build a product for the collaboration of developers.
An even better idea is a tool for collaboration between all kinds of people, not limited to developers.
I looked at the bigger picture.
Q: Why do we need augmentations?
A: Because we have a limited set of relevant labeled data.
Q: How else can we address the issue?
In practice, if such an option exists, everyone is just labeling more data.
It is relatively common to have a lot of unlabeled data, and you need to figure out what data to label.
After you have trained a model and checked its performance on the validation set, you have a collection of validation images on which the model is not performing well. Let’s call them hard samples.
The assumption is that if we add more data similar to these hard images and retrain the model, the model will improve its performance.
“Similar” is not a well-defined term. It could be:
- Way the model performs. Image A and B are similar because model XXX is not performing well on both.
- Color distribution. I had a situation when the train set was collected in summer, but in fall, it became darker, and model performance decreased.
- Semantics: Images A and B are similar because they have the same set of objects. For example, a raccoon.
- Any other distance metric. What type of similarity to use depends on the problem.
The first case is called Active Learning, and almost all ML Engineers implement something like it at some point in their career. By the way, augmentations add a lot of value here.
Right now, I would like to figure out how to adapt image search to add value to people.
For those who got to this point, I ask for a favor. Could you please go to the App and play with it? If you get an idea of how it could be valuable for you or someone else, please message me. All wild ideas are welcome.
I know that it is the technology in the search for the product which is anti-canonical, and that is why I am looking for pain :)



Comments