
Albumentations: Feedback

Warning: This text is dry, and its primary purpose is logging. It would be mainly helpful to those who already use the library.
I am one of the core contributors to the Open Source library Albumentations.
The library is used to augment images and is typically used to train neural networks.
To train neural networks, you need a lot of labeled data.
There are two ways to address this:
- Collect and label new data. It is expensive and slow but gives solid value.
- Augmentations. There is typically a value, but you do not know how much and how to choose them correctly. But you get them for free and right now.
In practice, you use both methods.
We have worked on the library for more than four years. Last year I wrote a long post on how the library was born and how we promoted it. [ The birth of Albumentations ]
Current traction:
- Five million downloads in total.
- 11k downloads per day
- 10k stars at GitHub (Do not forget to add yours if you did not already :) )
- Winners of all or almost all Computer Vision competitions at Kaggle use it in their solutions.
- The paper about the library has 700+ citations in the scientific literature.
- Cited in 10 books.
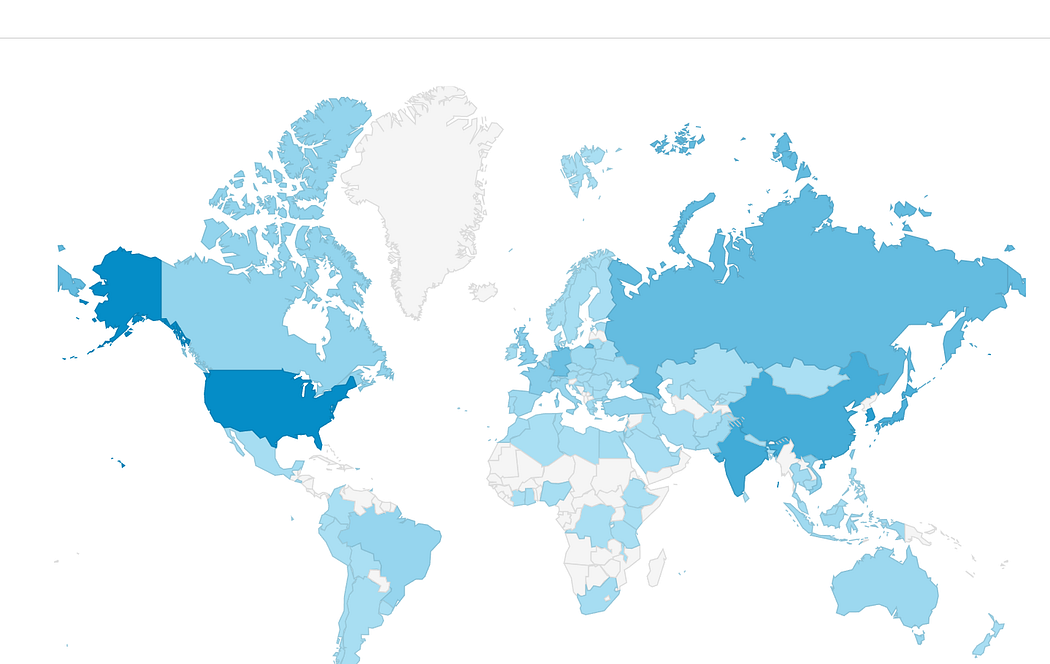
There are a few different reasons why the library took off. Functionality and good promotion are one thing, but the most important is performance.

From the authors of the Augly, developed at Meta at CVPR 2022.
We developed the library as a typical open source — the core team in different countries. When someone wanted to add a feature, he did this without planning, syncs, or OKRs.
After all these years of development, I decided to perform Customer Research and ask people how they use the library and what is missing.
I talked to 20+ people, and that is what I got:
Q: In what domains is the library used?
- All kinds of medical imagery.
- Document recognition.
- Satellite imagery.
- Autonomous vehicles.
- Robotics.
- Defect detection in the factories.
- Face recognition and antispoofing.
- Photo editing and enhancing.
- Road traffic monitoring.
- Beauty industry
- Retail
- Model testing and robustness to the data drift.
- Video processing from sports events.
- Mem generation.
If people need to train models on images or videos, they use Albumentations.
Q: What types of problems do people solve with Albumentations?
- Classification
- Object Detection
- Semantic and instance segmentation
- Action recognition
- Pose estimation
- Super Resolution
- Image inpainting
- Matting
Initially, we developed the library for classification and semantic segmentation. We added the rest of the functionality later. And it looks like it was worth it :)
Q: What is lacking?
- Images with examples to the documentation.
- Instruction on how to add new transforms.
- GPU support. There are Image Augmentation libraries that work on GPU, say DALI or Kornia, but they lack much of the functionality that Albumentatons have.
- 1D and 3D support. Video processing (XYT) and real 3D, as in medical imagery (XYZ) become more common. There are libraries such as Monai and Volumentations, but they are far from perfect.
- Export the augmentation pipeline from python to other languages such as C++ or Swift.
Q: What new transforms could be added?
- Add random text to images. Similar to what TextRecognitionGenertor does.
- AugMix, CutMix, MixUp.
- CutAndPaste — you have an object, and you need to add it to various background images filling the boundaries with inpainting or Poisson Blending.
- Add a mask or glasses to the face. As I understand, you find facial key points and use them.
- More ImageCompression transforms. We now have Webp and Jpeg formats, but we could add heic and jpeg2000.
- Mosaic Transform — you combine a few images into one big one. It is used in Yolo V4.
- In all dropout transforms, do not zero out but convert target pixels to the grayscale.
- Transform regions only inside of the bounding boxes.
- Transform regions inside of the specified mask. Use case — you need pants of various colors. You segment them beforehand and apply color transforms where the mask is nonzero.
Q: What non-standard transforms work well?
- In the tasks where you have an imbalance of the people with different skin color, say a lot of middle-aged white people, but not enough young black FDA transform works well.
- FDA, RandomSunFlare, and RandomFog in document recognition.
- ImageCompression in all situations where you have an old cell phone or bad camera images.
Q: How do people choose what augmentations to use?
There are different ways, and there is no one best practice so far:
- Pick a similar ML competition at Kaggle and use transforms from the winning solution.
- From previous tasks that the current ML Engineer worked on. Typically a person has three sets of the augmentation pipeline: light, medium, and heavy, and this is a good starting point.
- Pick transforms that do not affect the original distribution, say HorizontalFlip for natural images or D4 for satellite imagery.
- Use a Jupyter notebook or visualization tools like this one. (It was not updated for a while; feel free to submit pull requests to add new transforms.
In general, there is a feeling that the task of choosing a proper augmentation pipeline is not solved yet. It is a business opportunity to create a tool that takes a training dataset and returns a strong augmentation pipeline.
But there are a few problems:
No one knows how to choose such a pipeline. There is research in the domain of AutoAugment, which is a subset of even more popular AutoML, but it is in its early stages. Augmentations depend not only on the dataset and task but also on the model. The heavier model you use, the stronger augmentations you can apply. Augmentations add to the accuracy and generalization ability of the model. The smaller the dataset — the more value they add. The problem is that it is unclear beforehand how much value will be added if any. Returning to the library, we have good documentation and functionality, but much could be done.
If you want to contribute to Open Source and have never done it before — you are welcome. We have a lot of simple tasks for you :)
In general, we would like someone to work full-time on the project, but it looks like we need to set up a donation system. It seems like with the current traction, we may succeed in this :)


Comments