
Multi-target in Albumentations

This article was originally posted at Medium.
I am one of the authors of the image augmentation library Albumentations.
Image augmentations is an interpretable regularization technique. You transform the existing data to generate a new one.

You can use the library with PyTorch, Keras, Tensorflow, or any other framework that can treat an image as a numpy array.
Albumentations work the best with the standard tasks of classification, segmentation, object, and keypoint detection. But there are situations when your samples consist of a set of different objects. Multi-target functionality specifically designed for this situation.
Possible use cases:
- Siamese networks
- Sequential frames in the video.
- Image2image.
- Multilabel segmentation.
- Instance segmentation.
- Panoptic segmentation.
A few buzzwords
- The library emerged from the winning solutions in machine learning competitions. The core team includes one Kaggle Grandmaster, three Kaggle Masters, and one Kaggle Expert.
- Selim Seferbekov, the winner of the $1,000,000 Deepfake Challenge, used albumentations in his solution.
- The library is part of the PyTorch ecosystem and the Nvidia Inception program.
- 5800+ stars at the GitHub.
- 80+ citations in scientific papers. The library was mentioned in three books.
For the past three years, we worked on functionality and optimized for the performance.
Now we focus on documentation and tutorials.
At least once a week users ask to add support for multiple masks.
We already have it for more than a year. :)
This article will share examples of how to work with multiple targets with albumentations.
Scenario 1: One image, one mask
The input image and mask.
The most common use case is image segmentation. You have an image and a mask. You want to perform a spatial transform of both image and mask, and it should be the same set of transforms. Albumentations takes care of this requirement.
In the following code, we apply HorizontalFlip and ShiftScaleRotate.

Scenario 2: One image and several masks

Input: one image, two masks
For some tasks, you may have a few labels corresponding to the same pixel.
Let’s apply HorizontalFlip, GridDistortion, RandomCrop.

Scenario 3: several images, masks, key points, and bounding boxes

You may apply spatial transforms to multiple targets.
In this example, we have two images, two masks, two bounding boxes, and two sets of keypoints.
Let’s apply the sequence of HorizontalFlip and ShiftScaleRotate

FAQ
Q: Can we work with more than two images?
A: You can use as many as you want.
Q: Should the number of image, mask, bounding box, and keypoint targets be the same?
A: You can have N images, M masks, K key points, and B bounding boxes. N, M, K, and B could be different.
Q: Are there situations where multi-target will break?
A: In general, you can use the multi-target functionality to a set of images of different sizes. Some transform depends on the inputs. For example, you cannot perform a crop that is larger than the image. Another example is MaskDropout that depends on the input mask may. How will it behave when we have a set of masks is unclear. We will test these corner cases. But they are pretty rare in practice.
Q: How many transforms could be combined together?
A: You can combine the transforms into a complex pipeline in a number of ways.
We have more than 30 spatial transforms. All of them support images and masks, most of them support bounding boxes and key points.
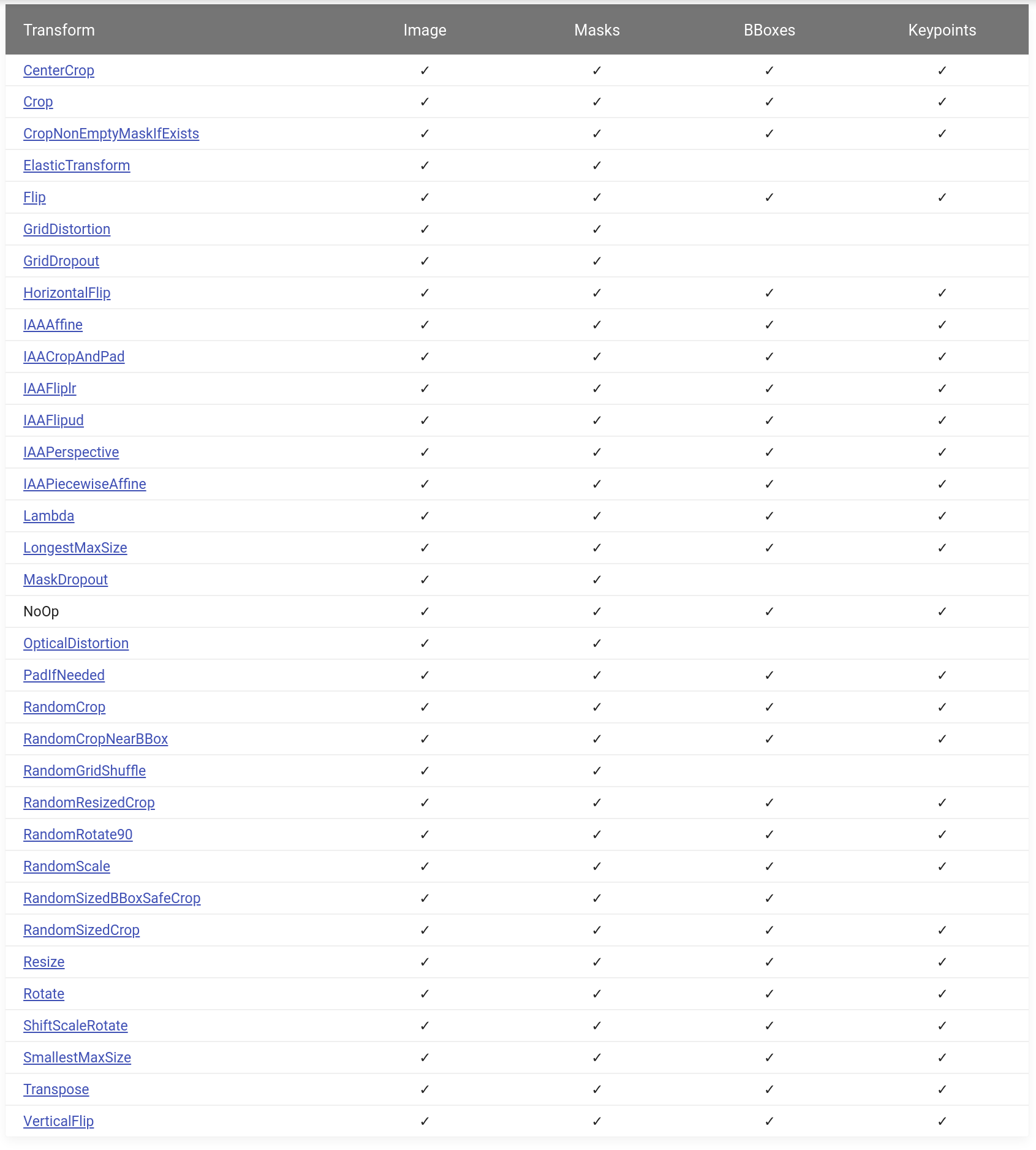
That could be combined with 40+ transforms that modify pixel values of the image. Example: RandomBrightnessContrast, Blur, or something more exotic like RandomRain.
More documentation
- Full list of the transforms
- Mask augmentation for segmentation
- Bounding boxes augmentation for object detection
- Keypoints augmentation
- Simultaneous augmentation of multiple targets: masks, bounding boxes, keypoints
- Setting probabilities for transforms in an augmentation pipeline
Conclusion
Working on the open-source project is challenging, but very exciting. I would like to thank the core team:
and all the contributors that helped to build the library and get it to its current state.
Translations to other languages
Russian
- At Habrahabr


Comments